Previously I have mostly used toggling, adding oder removing classNames from a classList with JavaScript. As these names suggest, they work with classList.toggle('className'), classList.add('className') and classList.remove('className'). For a recent project, I wanted to empty the complete classList of all its className tokens, which made me wonder what the best way to do so would be.
Just like the ways to Rome, there are multiple ways to remove all of your classNames in a class attribute, which all yield the same result. Let's have a look at the possibilities:
First, it is possible to toggle a className, which removes the className if it exists and otherwise adds ist to the classList. Yet this didn’t solve my problem.
element.classList.toggle('is-hidden');
One simple way to completely remove all tokens is to set the class attribute with setAttribute to an empty string, like so:
element.setAttribute('class', '')
Another option is to iterate over all the classNames in the classList and remove the first className as long as classNames can be found. By looking at the following code, I’m not sure why I would pick this, just for the amount of code required. Yet it works absolutely fine.
var classList = element.classList;
while (classList.length > 0) {
classList.remove(classList.item(0));
}
What I didn’t know is that with ES6, the spread operator (which consists of three periods) offers another simple way to clear a classList. The spread operator description says: “Spread syntax can be used when all elements from an object or array need to be included in a list of some kind.“ This is exactly what was needed in this case.
For my classList example with the spread operator, the syntax also is a one-liner, as compact as the first example above:
element.classList.remove(...element.classList);
From a quick search on the performance difference between setAttribute and using the …, it seems that the latter is slightly slower, but performance is not an issue for what I’m using it for.
I hope this has been helpful and thanks for reading this far. The documentation lists lots of other helpful cases for use of the spread operator, it’s worth checking out.
Update:
Thanks to Šime Vidas via Twitter here‘s the probably simplest one-liner that again does the same thing:
This is a very comprehensive post by Will Boyd on the ::before and ::after pseudo-elements which covers basically everything you need to know to make use of them is a variety of scenarios.
I especially like the accessibility section at the end, which is will make a huge difference if we include this little extra in the future.
Some things have to end and this time, after more than three years, it is Colloq.io that we are shutting down at the end of March 2021. It’s quite sad, but at this time the sensible thing to do. It’s been a fun ride, I learned a lot, we build some great things. We had our “ethical shit” together and went privacy-protect-crazy, yet unfortunately, it needed more than that (or maybe less?), and in the end we didn’t make it work out.
But hey, as they say: If one door closes, another one opens. Or in this case, re-opens. Here’s a small sneak peek of what I’m currently working on.
It's been exactly one year to this day that I posted “Escaping the Virus”, which in hindsight makes an interesting read and perspective, because we had no idea what was yet to come…
A lot of things happened during that last year and the situation somehow resulted in me taking a big break from blogging and social medias of all kinds. I didn’t miss it much, but it’s a good time to return now and show this site some love again.
While at first I didn't like the title “Why is CSS Frustrating?”, I finally got to read it and it covers a few good points. I think I still don’t like the title much, since it seems to establish an incorrect fact, or rather a fact for some people. You could say the same thing about other languages and things to learn, depending on your experience, preference or personal learning curve.
The final sentence though makes perfect sense, and is a general good advice, not only for learning and understanding CSS.
It’s been a few weeks that Hong Kong has been hit with the Covid-19 virus situation and since then, life hasn’t been quite the same. Somewhere between worried and not, because chances to get infected should be rather small, most conversations around friends have mainly been around the virus or at least always touched the topic. The list of services and shops that have shut down or at least have adjusted their operations is quite long.
The situation has had a big impact on the quality of life. Masks are everywhere and only a few people don’t wear them. Every time you touch a door handle, press buttons in a lift, you automatically think about it. Washing hands all the time. After some time the situation isn’t enjoyable anymore and gets quite depressing.
Luckily and due to some virus-related circumstances I‘ve been offered the opportunity to go to Thailand and stay and work from a friend’s house. It’s been a rather easy decision to make and I took the chance to try the “digital nomad remote working” thing.
Today is only day two, but it’s great to not have to worry about masks or disinfectants anymore. On the plus side, it’s nice to wake up having the option for a morning swim in the sun. I’m curious to see how this experiment will pan out in terms of productivity and getting things done. So far it feels super nice and it makes you think why anyone ever had the idea of putting everyone into an office…
Pretty nice that the proposed native lazy-loading for images or rather the loading attribute now made it into the HTML standard. A while ago Chrome started out with this idea and from now on it is also supported in Firefox Nightly. I've been using native lazy-loading for images on this site for a few weeks to try it out, and added it to a Kirby plugin for optimised images. It seems lazy-loading will stay on this site for a longer time now :)
A few days ago Addy Osmani shared this new editor typeface: JetBrains Mono. I had a look at it and liked it right away, so I installed it as my new editor font. So far I really like it, and the more I look at it the more beautiful I find it. I’m curious to see how long I will keep using it, I’ve had some of the previous for a long time, while others haven’t lasted long. So far I think JetBrains Mono might last a longer time. Let’s see.
The most common misunderstanding of progressive enhancement is that it’s inherently about JavaScript. That’s not true. You can apply progressive enhancement at every step of front-end development: HTML, CSS, and JavaScript.
[…]
Separating out the layers of your tech stack isn’t necessarily progressive enhancement. If you have some HTML that relies on JavaScript to be useful, then there’s no benefit in separating that HTML into a separate payload. The HTML that you initially send down the wire needs to be functional (at least at a basic level) before the JavaScript arrives.
This is a great article on the "approach and mindset" of progressive enhancement. I really like this phrase. After so many years of talking about progressive enhancement, it’s still being widely misunderstood. Also still not cool. While I still think that the PE approach is such a great approach—it doesn't really matter what and how you’d like to enhance—I’ve always felt there are a few reasons, why it never really caught on, or rather became widely practiced:
It can be a lot of work, if e.g. you want to provide a non-JS solution for everything as a fallback;
A lot of budgets aren’t big enough to cover this amount of work (or PE is not important enough…);
You need to know and understand a lot of web technologies. And if you do, go back to 1.
Today I had a little time to catch up with the growing list of unread articles in my RSS reader and came across this short post on Marc’s blog. It’s so simple and I wholeheartedly agree. The below quote is from 2006, but it well stands the test of time. It is such a great answer to what a blog is:
[…] it’s this record of who you are, your persona […]
I was playing around with CSS transforms on an element with a border, where as a result the border would then overflow the page body. Usually this would not be an issue that the CSS property overflow couldn’t solve. To be more precise, in my case the correct property to use was overflow-x with the value of hidden to avoid horizontal scroll, since by using overflow: hidden the main page content, which is (likely) longer than the viewport, would stop scrolling vertically. And that would be bad.
After adding overflow-x: hidden to my transformed element, I started testing in different browsers. It seemed to work just fine, but after deploying I noticed that Safari and Chrome on iOS as well as Firefox, rendered the page with horizontal scrolling. I was a little surprised and at first, I thought that it had to be a bug with overflow-x.
I went on to check the examples on MDN and all of them worked fine in either browser. I then started to read the specification for the hidden value of overflow and there I found the solution:
hidden
This value indicates that the box’s content is clipped to its padding box and that the UA must not provide any scrolling user interface to view the content outside the clipping region, nor allow scrolling by direct intervention of the user, such as dragging on a touch screen or using the scrolling wheel on a mouse. However, the content must still be scrollable programatically, for example using the mechanisms defined in [CSSOM-VIEW], and the box is therefore still a scroll container.
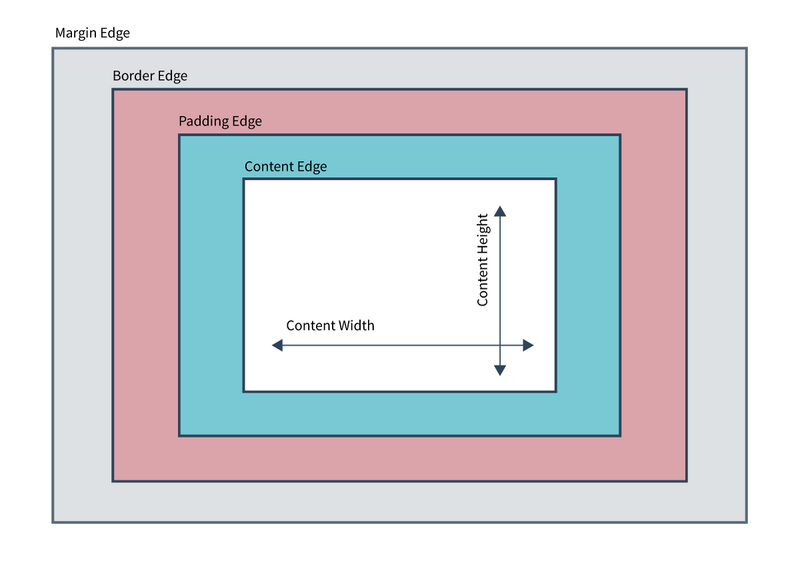
The specification says “fit the padding box”. To understand the problem, we need to take a look at the CSS basic box model.
When laying out a document, the browser's rendering engine represents each element as a rectangular box according to the standard CSS basic box model. CSS determines the size, position, and properties (color, background, border size, etc.) of these boxes.
Every box is composed of four parts (or areas), defined by their respective edges: the content edge, padding edge, border edge, and margin edge.
Diagramm of the CSS Basic Box Model
As visible in the above diagram, the border edge lies outside the padding edge and because of that, the clipping of overflow didn't work as expected. I then refactored the element to use a margin instead of border and it now works as expected. Another positive side effect of changing the border to a margin is that it removes some rendering issues (in Safari) on the border which can appear when an element is transformed.
An example of a rendering issue in Safari on a border when using transform skew
After so many years of working with CSS I didn’t think there was something new to learn about the overflow property, but oftentimes a language specification will surprise you in the most unforeseen ways ;) I recommend taking a peek once in a while, because there’s always something new to learn and it’s absolutely worth it.
Today, 02.02.2020, is a special day, because today’s date is a palindrome, which can be read forwards as well as backwards. What makes it even more special is that a date like this will occur only once this century.
This rather fun and entertaining video provides the full explanation of why, how and when such dates did and will occur again, plus a few more interesting tidbits.
“A brand is not what you say it is. It’s what they say it is.“
I really like this quote which opens Matthias’ post. I wanted to put this down, just to remember it.
Recently Matthias has been putting out some great stuff and it’s great to read this article and think: “It’s getting better indeed”. This post is about “thoughts on writing” and I really love it. It’s so spot on and there are many things in there which of course seem obvious in hindsight, but it’s great to read, and have the sometimes obvious put in good words.
“ Only by publishing your work and placing it out in the world and in front of other people it is truly complete.”
A happy Chinese new year! Today is already the second day of the lunar new year and this year, it is the year of the rat. It also marks the eleventh CNY to me, which takes it almost full circle in the twelve zodiacs. Hopefully this year will be a better one, the previous ones haven't been so amazing, but I've heard that this one will be good for tigers. Usually I always get and read the Chinese horoscope for the new year, but I haven’t gotten around to get one yet. It’s always a fun read and surprisingly and without being especially superstitious, it’s often been quite right in many ways. I hope that all of you will have a great year head, wether you’re into CNY or not, yet it’s always nice to get to celebrate a second start of the year.
A new year, a new Kirby update, 3.3.3-rc.1. I guess there’s not that much to report, besides the fact that it is available and I’m giving it a spin on this site at the moment. It all seems to work fine. The download of this latest package is available from the releases page.
After yesterday’s post on Digital Gardens and how to possibly arrange information, posts and all that in a better or more interesting and fun way, I started to try a few things. One of the approaches is to not list articles, notes and other things separately anymore, but instead list them all together, maybe with a marker for each type.
While trying to figure out how to best achieve this, I came across two helpful ways on how to do it in Kirby:
Option 1: $pages->add() which lets you add additional pages or collections to collections;
Option 2: $pages->merge() which merges one collection with one or more other ones.
I'm not even sure what the exact difference between the two methods is, since they do seem quite similar. I opted for $pages->merge() and the code in progress currently looks like this and works pretty nicely:
This article and the idea of a “Digital Garden” also got me thinking about the way information could be presented and I like the idea of curating content for sections a bit more.
For quite some time I’ve been thinking about what to do with my Notes section, if it might be redundant or could be combined with others. The more I think about it the more I start to like the idea of one section with “Everything”, that can be filtered, e.g. by long and short reads and what other content types there might be.
Every few months things want to be changed around, but the holy grail is yet to be found ;)
What are your thoughts and ideas to make blogs more interesting? What are ideas so we can push the boundaries and do things differently, even if just for the sake of exploration? There’s still so much that could be done, yet the patterns have mostly stayed the same for many years… I’d love to hear your progressive or other thoughts on this.
I did skip the last update to 3.3.1 because I didn’t find the time, but have finally managed to update my site to the latest Kirby 3.3.2. After the rather huge update to 3.3.0, the last two releases feature more fixes and enhancements, yet it’s great to see constant improvements and additions, aka active development. It’s for sure the most fun CMS I have had my site on so far and I enjoy it a lot.
Today I read about the new CSS :is() pseudo-class function and at first thought, that it doesn’t seem helpful and all of what it does can already be achieved without it. I looked at some of the examples and it turns out that it can actually be quite helpful and in some cases much more convenient than the current approaches.
The new CSS :is() pseudo-class is shaping up to become a great way to target elements, saving on lines and lines of code, and keeping CSS as readable as possible. It is the next stage of the evolution of :matches() and :any(), adding a little extra functionality and increasing how semantic and intuitive the language behind selectors is.
This example from its MDN docs makes it quite clear how :is() can simplify the way we write CSS. Currently a lot of CSS looks like this:
section section h1, section article h1, section aside h1, section nav h1,
article section h1, article article h1, article aside h1, article nav h1,
aside section h1, aside article h1, aside aside h1, aside nav h1,
nav section h1, nav article h1, nav aside h1, nav nav h1 {
font-size: 20px;
}
With :is() the above block can be simplified quite a bit:
Browser support for :is() is at around ~60% globally and a few browsers still require a fallback solution, but I'm looking forward to use this in one of my next projects to try it out.
I was working on a very simple “email this article as a recommendation” feature, where the user would click a link to open their email client with a pre-populated subject and email body. The link looks like this:
The issue I ran into showed up when the article title contained special characters and especially an ampersand (&), since that would cut off the subject line, because it would signal the beginning of the next paramater. This feature is for a Kirby site and I tried a few different PHP encodings to get around this problem. One of the obvious things to try was to urlencode() the string. Since urlencode() replaces the spaces with a “+” sign, it wasn’t the right choice. Eventually the solution was to use PHP’srawurlencode() for the subject text, which uses “%20” for spaces which are later invisible in the subject line.
It took a long time for accessibility to get the deserved recognition it has today and with so many different people using the web, the importance of building accessible interfaces has increased ever more. There will always be room for improvement and getting things right can still be challenging and requires care, but the resources to do so are getting better and better. So does the awareness. Inclusive Components is a great addition to these resources, taking a practical approach to explaining how to build fully accessible UI components with a lot of examples. Understanding and embracing how to build accessible interfaces will improve the quality of our work, but more importantly, it can—sometimes drastically—improve the experience of our users in many ways.
Inclusive Components by Heydon Pickering - Accessible web interfaces, piece by piece
In its heart, "Inclusive Components" is a detailed, practical handbook for building fully accessible interfaces. It's also a guide towards accessibility-focused thinking when designing and building websites and apps today. Our hope is that we've managed to produce a book that would make accessibility more approachable to everybody involved in any web project.
Dealing with Ads in 2020 is an interesting look at the problems and challenges of integrating and displaying ads in the best possible way.
The article slash case-study from Christian Schaefer [“Schepp”] shows the approach they took at Rheinische Post Mediengruppe to implement and deliver ads in a better way than most sites currently do, taking into account responsiveness, lazy loading as well as considering network speeds and security to improve the experience.
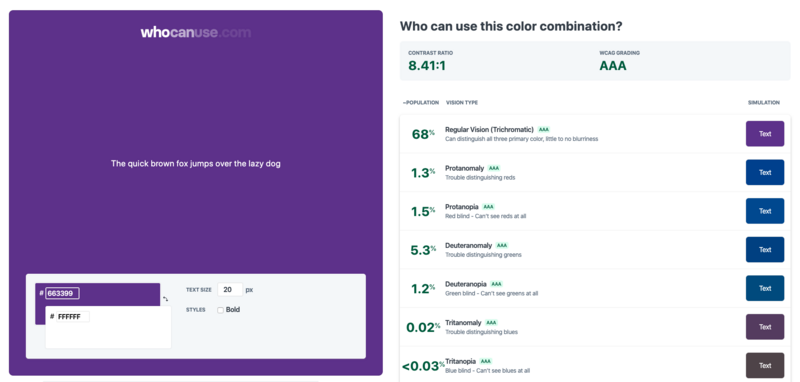
WhoCanUse is a helpful tool to test the color contrast of different color combinations and informs you about the contrast ratio and the WCAG grading. While it might not be 100% perfectly accurate, it provides a good indication of how well the colors work for the various vision types. Interestingly enough, there are a lot of vision types that I wasn‘t aware of at all.
What is whocanuse.com?
It's a tool that brings attention and understanding to how color contrast can affect different people with visual impairments.
The Web Content Accessibility Guidelines (WCAG) covers a wide range of recommendations for making Web content more accessible. Just a tiny part of making the web more accessible is accommodating for those with a form of blindness or low vision.
 Clearing a classList (with the JavaScript Spread Operator)
Clearing a classList (with the JavaScript Spread Operator)